Como as regras são organizadas na memória.
O HLBR não processa as regras uma a uma, como pode parecer. Ao invés disso ele processa os testes contra cada pacote, cada teste estando ligado a uma ou mais regras.
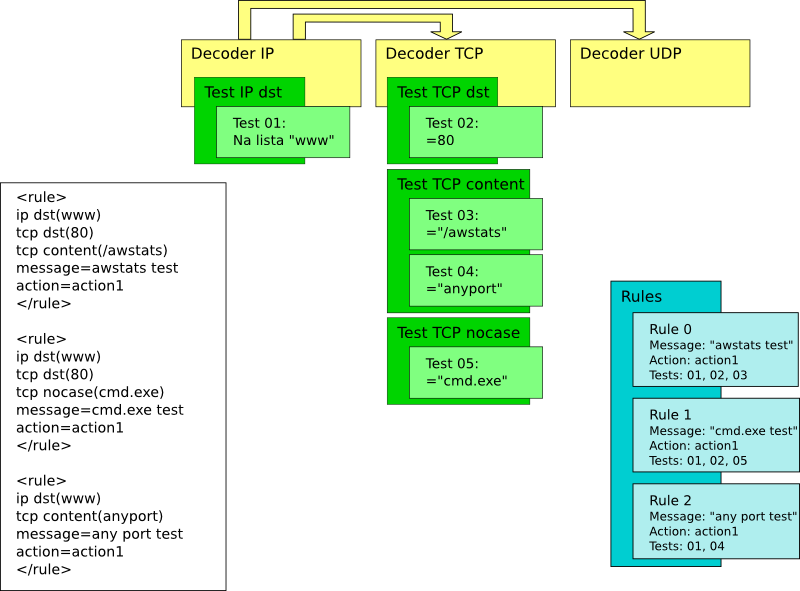
Eis o que acontece. Suponha que o HLBR seja executado com as três regras abaixo:
<rule> ip dst(www) tcp dst(80) tcp content(awstats) message=awstats test action=action1 </rule> <rule> ip dst(www) tcp dst(80) tcp nocase(cmd.exe) message=cmd.exe test action=action1 </rule> <rule> ip dst(www) tcp content(qqporta) message=qqporta test action=action1 </rule>
Quando o HLBR lê as regras, ele dá a cada uma um número começando de 0.
Então, basicamente:
Para cada pacote que o HLBR testa com estas regras, ele vai executar os passos a seguir. Tenha em mente que os testes vão acontecendo à medida em que o pacote vai sendo decodificado; primeiro entra em ação o decodificador de pacotes IP (IP decoder), que verifica se o pacote é um pacote IP. Se for, ele executa os testes apropriados. Logo em seguida ele executa os demais decodificadores que estão ligados ao IP (TCP e UDP), e assim por diante. Logo, as regras serão executadas assim:
Depois disso ele passa para o teste 'tcp nocase', e segue adiante, repetindo este processo. Ou seja: as regras não são processadas por inteiro, mas partes das regras são processadas à medida em que o HLBR passa pelos diferentes testes.